Iteratively raises $5.4M to help companies build data pipelines they can trust – TechCrunch

[ad_1]
As companies gather more data, ensuring that they can trust the quality of that data is becoming increasingly important. An analytics pipeline is only as good as the data it collects, after all, and messy data — or outright bugs — can easily lead to issues further down the line.
Seattle-based Iteratively wants to help businesses build data pipelines they can trust. The company today announced a $5.4 million seed funding round led by Google’s AI-centric Gradient Ventures fund. Fika Ventures and early Iteratively investor PSL Ventures also participated, with Gradient Ventures partner Zach Bratun-Glennon joining the company’s board.
Patrick Thompson, Iteratively’s co-founder and CEO, started working on Iteratively about two years ago. Before that, he worked at Atlassian and at Syncplicity, where he met his co-founder Ondrej Hrebicek. After getting started, the team spent six months doing customer discovery and the theme they picked up on was that companies weren’t trusting the data they captured.
“We interviewed a ton of companies who built internal solutions, trying to solve this particular problem. We actually built one at Atlassian, as well, so I was very much intimately familiar with this pain. And so we decided to bring a product to market that really helps alleviate the pain,” he told me.
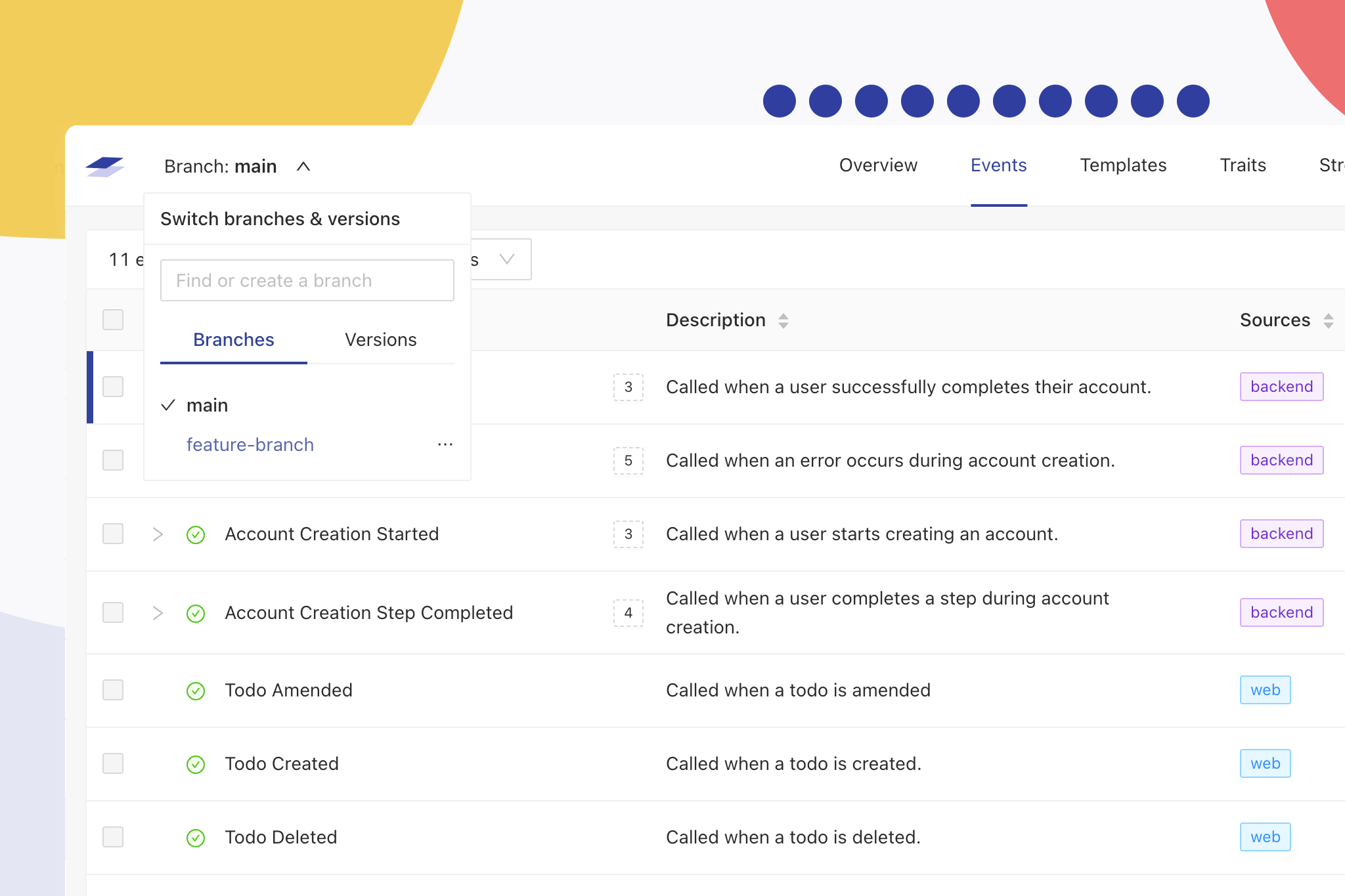
Image Credits: Iteratively
In a lot of companies, the data producers and data consumers don’t really talk to each other — and if they do, it’s often only through a spreadsheet or wiki. Iteratively aims to provide a collaborative environment to bring these different groups together and create a single source of truth for all stakeholders. “Typically, there’s a handoff process, either on a JIRA ticket or a Confluence page or spreadsheet, where they try to hand over these requirements — and generally, it’s never really implemented correctly, which then causes a lot of pain points down down the line,” Thompson explained.
Currently, Iteratively focuses on event streaming data for product and marketing analytics — the kind of data that typically flows into a Mixpanel, Amplitude or Segment. Iteratively itself sits at the origin of the data, say an app, and then validates the data and routes it to whatever third-party solution a company may use. That means the tool sits right where the data is generated, but this setup also means that none of the data ever flows through Iteratively’s own servers.
Image Credits: Iteratively
“We don’t actually see the data,” Thompson stressed. “We’re not a data set processor. We’re a wrapper over the top of your own analytics pipeline or your own third-party SaaS tools, but we verify the payloads as they flow through our SDK on the client.”
Over time, though, that may change, he acknowledged and Iteratively may do some data processing as well, but likely with a focus on metadata and observability.
Since the company doesn’t actually process any of the data itself, it’s charging customers by seat and not based on how many events move through their pipelines, for example. That may obviously change over time as the company looks into doing some data processing on its side as well.
Currently, Iteratively has about 10 employees and plans to grow that to 20 by the end of the year. The company plans to hire across R&D, sales and marketing.
“Iteratively‘s software has a unique approach to enabling company-wide collaboration and enforcing data quality,” said Gradient’s Bratun-Glennon. “Going forward, we believe that intelligent analytics and data-driven business decision making will differentiate successful companies and best-in-class products. Iteratively‘s mission, product and team are poised to give each of their customers these capabilities.”
[ad_2]
Source link